Bonjour tout le monde, j’écris ce post pour raconter un problème de lock rencontré à mon travail. C’était intéressant à investiguer donc autant le partager et à la fin je présenterai un outil créé pour l’occasion 🙂
Disclaimer : Par soucis de confidentialité et d’accessibilité, j’ai simplifié la situation au maximum, j’ai mis des screenshots floutés, utilisé des faux noms.
La demande
Il y a quelques semaines, mon équipe a reçu une demande de support d’un développeur (que j’appellerai Bob) sur un problème qu’on aurait pu résumer par : “Nos utilisateurs se plaignent que, de temps en temps, leurs demandes ne puissent pas aboutir. J’ai regardé les logs de mon application et on dirait qu’il y a des timeouts coté Sql Server”.
Un de mes collègues DBA (que j’appellerai Henri de Bessancourt) a identifié avec le développeur quelle procédure stockée partait en timeout de temps en temps. Il l’a exécuté en quelques millisecondes et en a donc conclut que ce n’est pas cette requête qui était lente mais qu’il devait s’agir d’une autre requête qui bloquait celle ci (c’était une requête simple sans possibilité de mauvais plan d’exécution et de parameter sniffing). Des demandes comme celle-ci, on en a régulièrement, on gère des centaines de bases réparties sur des centaines de serveurs donc impossible de connaitre chaque process de chaque base. De plus, sur ce serveur, on est entre 5 et 15k batch requests/ seconde, il faut donc cibler les recherches.
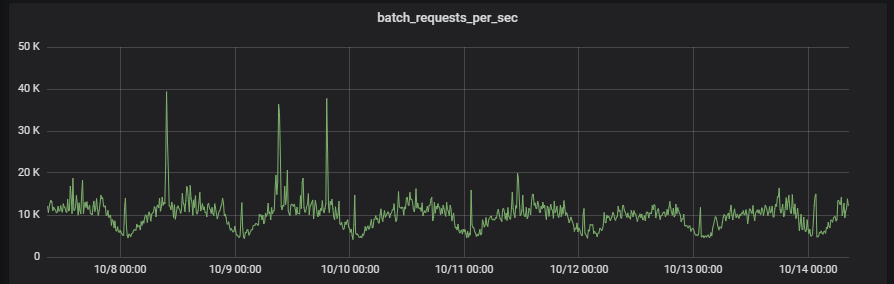
Henri a donc fait ce qu’on fait régulièrement pour investiguer, il a créé une trace pour détecter les requêtes qui durent plus de X secondes.
Quelques heures plus tard, Bob est revenu voir Henri et lui a dit : “J’ai eu 2 timeouts à 10h03 et 11h02, alors quelle requête lente bloquait tout ?”
Henri a regardé la trace mais : “Je n’ai détecté aucune requête lente”
Henri a vérifié que sa trace fonctionnait bien et a décidé de créer une trace qui allait collecter les locks.
(Je ne sais pas vous, mais moi, ce genre de trace, je les trouve juste illisible. On a utilisé une trace mais même avec les extended events je suis assez mitigé sur leur lecture)
Quelques temps plus tard, Henri a lu le résultat de la trace et a pu constater que la requête était bien bloquée par une autre session, mais il n’a pas réussi à trouver ce que cette session bloquante faisait.
Au gré des projets et autres taches, j’ai repris le sujet à ce stade. Je savais qu’il y avait des requêtes lockées mais qu’Henri ne savait pas par quoi. Aussi pour essayer de comprendre ce qu’il se passait dans cette base de données, j’ai décidé de lancer de nouvelles traces. Toujours pareil, dans la trace, au lieu de trouver la requête bloquante, je me retrouvais uniquement avec un id de session mais sans plus d’information.
L’artillerie lourde
C’est à ce moment où ca a commencé à m’intéresser vraiment. Pourquoi je n’arrivais pas à récupérer la cause du blocage avec une trace. Alors j’ai fait le bourrin ! C’est vrai si la trace était incapable de faire le travail, que j’arrivais à savoir quelle session était bloquée et quelle session était bloquante, il suffisait de consulter les DMV et tables systèmes pour percer les mystères. J’ai donc pris la requête que j’utilise dans le live session de Kankuru, parce qu’elle permet de voir les requêtes en cours et si elles sont bloquées. Je l’ai un peu allégée et triturée pour en faire une requête qui allait sélectionner les requêtes bloquées ainsi que les informations de la session bloquante et de la jouer en boucle.

;WITH cte AS
(
SELECT CAST(qe.session_id AS VARCHAR) AS [Session_Id]
, blocking_session_id
, db_name(qe.Database_id) AS [DatabaseName]
, s.login_name
, s.host_name
, s.program_name
, s.client_interface_name
, start_time
, qe.logical_reads
, qe.writes
, qe.cpu_time
, qe.command
, a.text AS [Query]
FROM sys.dm_exec_requests qe (NOLOCK)
INNER JOIN sys.dm_exec_sessions s (NOLOCK) on qe.session_id = s.session_id
LEFT JOIN (select sqe.session_id
, st.text
FROM sys.dm_exec_requests sqe (NOLOCK)
CROSS APPLY sys.dm_exec_sql_text(sqe.sql_handle) st) a
ON qe.session_id = a.session_id
WHERE qe.session_id != @@SPID
)
SELECT c.Session_Id
, c.DatabaseName
, c.login_name
, c.host_name
, c.program_name
, c.client_interface_name
, c.command
, c.Start_Time
, c.cpu_time
, c.logical_reads
, c.writes
, c.Query
, c.blocking_session_id
, c2.blocking_session_id AS blocking_session_id_Lvl2
, db_name(s.dbid) AS blocking_DatabaseName
, s.loginame as blocking_loginname
, s.hostname as blocking_hostname
, s.program_name as blocking_program_name
, c2.client_interface_name as blocking_client_interface_name
, c2.start_time AS blocking_start_time
, coalesce(c2.query, text2.text) AS blocking_Query
, s.cpu AS blocking_cpu
, s.cmd AS blocking_command
FROM cte c
LEFT JOIN cte c2 on c.blocking_session_id = c2.Session_Id
LEFT JOIN master.sys.sysprocesses s on c.blocking_session_id = s.spid
LEFT JOIN(
SELECT s2.spid
, st2.text
FROM master.sys.sysprocesses s2
CROSS APPLY sys.dm_exec_sql_text(s2.sql_handle) st2
) AS text2 ON s.spid = text2.spid
WHERE c.blocking_session_id != 0
WAITFOR DELAY '00:00:01' -- je l'exécute toutes les 1 secondes environ
GO 5000 -- je l'exécute 5000 fois... Bourrin ? Moi ? :)
Et là, ce fut le drame : avec cette requête, j’ai récupéré tout un tas de lock mais lorsque je suis tombé sur le lock de la table en question, je trouvais à nouveau le session id mais impossible de mettre la main sur la requête bloquante.

L’illumination
J’ai enfin eu l’illumination (il était temps !) : si je n’arrivais pas à récupérer la requête bloquante, c’était peut être parce que c’était une requête système. Et après un peu de réflexion, je me suis souvenu que cette base était en mirroring synchrone.
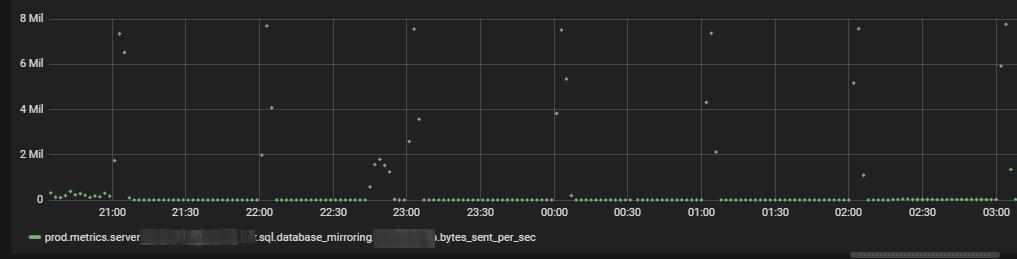
Après un peu de recherche dans notre outil de monitoring, je trouvais ce que je cherchais : des pics assez important en écriture sur le mirroring.
A la recherche de la requête perdue
J’ai donc repris la trace faite par Henri, pour déterminer quelle requête pouvait surcharger le mirroring. En effet, pour écrire autant, la requête ne pouvait pas durer 1 seule seconde, il fallait que ce soit bien plus long. Et à nouveau, aucune requête de plus de x secondes n’écrivait dans cette base de données.

Cependant, en regardant le graphique du mirroring, on voyait très clairement un pattern. Toutes les heures, il y avait pas mal de paquets envoyés. Ca ressemblait à un job planifié. Il ne restait plus qu’à déterminer lequel.
Et grâce à Kankuru, il suffisait de lancer le live session à la bonne heure pour trouver la requête…
Une dernière surprise
Je tenais enfin la requête qui posait problème et qui saturait le mirroring. En revanche, je ne comprenais pas pourquoi elle n’apparaissait pas dans les traces qui capturaient les requêtes lentes. En fait, quand on fait une trace pour capturer des requêtes qui durent plus de X secondes, la trace ne collecte que les requêtes qui aboutissent (suite au commentaire de Bruno, ceci reste à vérifier mais semble faux). Et en l’occurence, cette requete de suppression de lignes était exécutée depuis un client qui avait un execution timeout à 90 secondes.
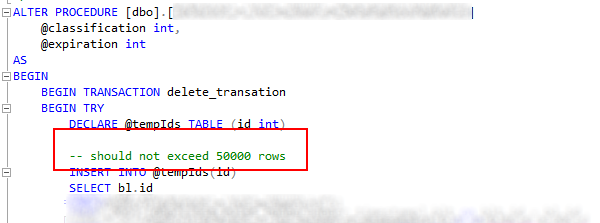
Et comme l’indique ce screenshot, dans une transaction, la procédure essayait de supprimer 32 millions de lignes dans 2 tables. Et pour en ajouter une couche, cette table et ce code n’avait plus aucune utilité.

Resumé
Voici donc un résumé simplifié de ce qu’il s’est passé :
Un code legacy, non monitoré, essayait de supprimer chaque heure 32 millions de lignes pendant 1 minute 30 puis faisait un rollback à cause du timeout. La suppression de ces lignes saturait le mirroring.
Pendant ce temps, les écritures sur une autre table de la même base étaient en attente de pouvoir commit au travers du mirroring. Puis les lectures étaient bloquées par ces écritures.
Conclusion
En conclusion, avant de vous montrer la nouvelle fonctionnalité de Kankuru, voici quelques rappels :
- Supprimez le code et les données que vous n’utilisez plus
- Monitorez chacun de vos process
- Chaque action réalisée sur une base de données peut bloquer quelqu’un d’autre, minimisez la taille de vos transactions
Live Lock Profiler
Puisque je me suis aidé d’une requête pour constater les locks sur la base, je me suis dit que ce serait intéressant d’en faire un outil que je partagerais grâce à Kankuru. Voici donc en avant première l’outil “Live Lock Profiler”. Il sera disponible dans la prochaine version de Kankuru.
Comme précisé plus haut, cette méthode consiste à interroger les DMV (la requête sql est disponible ici) très régulièrement pour capturer les requêtes bloquées et les requêtes bloquantes. Et comme j’ai ces données en mémoire, proposer des statistiques en temps réel.
Voici une très simple démo. Je vais dans un premier temps ouvrir une transaction qui écrit dans une table et mettre un timer pour conserver cette transaction ouverte :
BEGIN TRANSACTION
INSERT INTO [dbo].[Table_1]([largedata])
VALUES ('coucou, tu veux voir mon insert ?')
WAITFOR DELAY '00:50:00' -- oui j'attends bêtement 50 minutes
COMMIT TRANSACTION
Et puis dans une autre session SSMS, je vais tenter d’exécuter ce code qui sera bloqué par la requête précédente :
SELECT COUNT(*)
FROM dbo.Table_1
Et donc dans Kankuru, on obtiendra ce résultat :
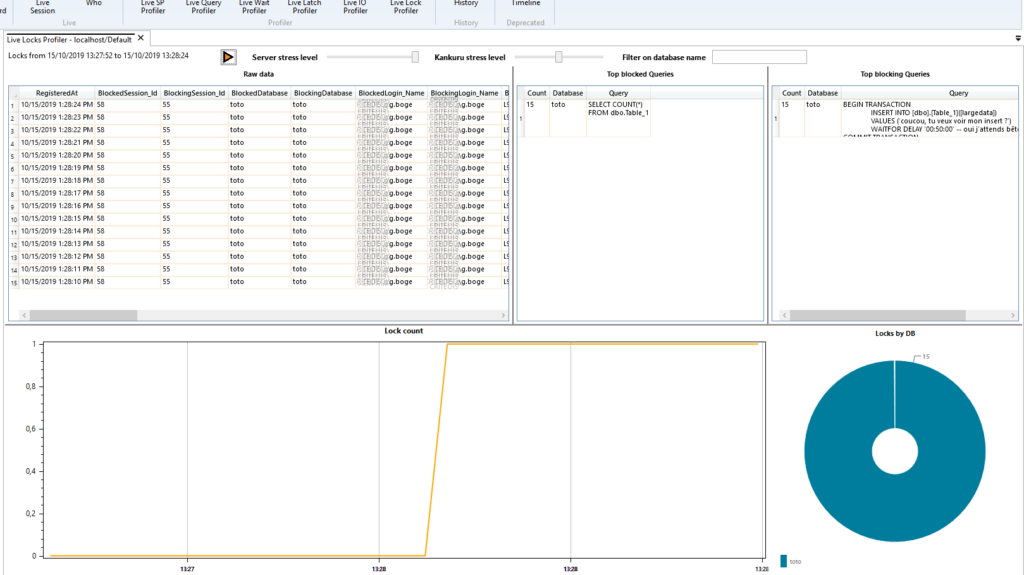
En haut de gauche à droite, les données brutes, puis la liste des requêtes les plus bloquées, puis celles qui sont le plus bloquantes. Et en bas, le nombre de lock dans le temps puis le nombre de lock par base de données.
Et voici une demo gif (full screen link)

Alors, impatient de l’utiliser et d’améliorer les performances de vos bases facilement ?
Joli travail.
Et de l’eau à mon moulin quand je dis que le mirroring doit être asynchrone sur un master. Oui, c’est cher, il faut de l’Enterprise Edition .
Merci Bruno, effectivement en asynchrone, à part un peu de latence sur le mirroir, on n’aurait pas eu tous ces locks. Mais oui, ça coute beaucoup plus cher en licence 🙂
Super boulot GREG, en revanche je me permet une remarque car je ne suis pas daccord sur “la trace ne collecte que les requêtes qui aboutissent”.
Dans le cas de timeout déclenché par ADO le profiler les remonte bien…
Cordialement
Salut Bruno, je viens de vérifier et tu as tout à fait raison !


J’ai fait un sqlcmd tout bete qui attend 10 secondes avec un execution timeout à 2 secondes et dans la trace, on voit bien la requête qui se termine:
Il faudrait que je reprenne toutes les traces qui ont été faites. Soit la trace filtre trop (ce qui est possible car j’ai simplifié pour l’article), soit je me suis raté en lisant la trace (c’est également fortement possible) soit ca ne fonctionne pas à l’identique en jdbc ou autre (mais j’ai quand même un doute), je ferai des tests la semaine prochaine 🙂
je me rends compte que les images ne sont pas trop lisibles, elles sont disponible ici :
image 1
image 2
J’ai mis à jour l’article en attendant de vérifier. Merci pour ton retour
Pingback: 1.4.9 - End of year release (live lock profiler) - Kankuru